This blog series explores how biological neural networks can be integrated into modern AI systems. The posts progress from practical applications to increasingly general principles, moving from perception to representation, dynamics, and ultimately algorithm discovery. This post focuses on generative video, showing how biologically derived neural dynamics improve stability and extend rollouts in modern video models.
Note: This is a living document, and we are building in the open. We expect frequent updates and actively welcome feedback from the community.
For the first time, we show that adding a small, biologically derived software module to a state-of-the-art video model enables longer and more stable video generation without full retraining. Building on earlier results in vision and representation learning, this work extends biological neural dynamics to temporal generative systems, with direct relevance for interactive games, simulations, robotics training, virtual worlds, and world models. Importantly, these results suggest that neural-based adapters can reduce the computational cost required to achieve high-quality, long-horizon generation.

Biologically inspired software enables AI videos to stay coherent for longer. Without our biologically derived adapter, AI-generated videos gradually fall apart as they get longer (left). With the adapter, the videos stay clearer and more consistent over time (right).
We invite bold teams working at the intersection of video generation, algorithm discovery and the future of compute to engage with us and explore how these approaches can unlock step-change performance, materially reduce compute costs, and help shape the next generation of computing systems.
While today’s generative video models can produce striking visuals, they struggle to maintain coherence over time. As rollout length increases, small errors accumulate, internal representations lose structure and outputs degrade, forcing applications to trade off quality, consistency, and computational cost. Biological neural networks are inherently optimized to preserve stable representations over extended temporal dynamics under tight energy constraints, making them well suited for extracting structure from sequential data.
We bridge this gap by introducing a new software module inspired by observed dynamics of biological neurons, specifically the patterns by which neural activity is locally organized and sustained temporally and spatially. This work is enabled by our biological computing platform, which interfaces directly with living neural networks on high-density multi-electrode arrays. By observing their spatiotemporal dynamics over repeated experiments and systematically translating these observations into computational primitives, we uncover algorithmic representations that can be incorporated into modern generative models in a controlled and reproducible way.
By integrating these biologically derived dynamics into interactive world generation, we achieve a visible improvement in long-horizon rollout stability. The result is the ability to generate significantly longer, high-fidelity video sequences that remain coherent over time, providing a more robust foundation for persistent digital environments.
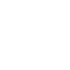
We used the open-source 600M-parameter Oasis Minecraft world generation model, which leverages a Diffusion Transformer (DiT) and player action conditioning to enable interactive gameplay. The DiT operates as the frame-predictor backbone within a latent space defined by a spatial autoencoder based on the Vision Transformer architecture (Figure 1).
The base model adopts diffusion forcing techniques during training with independent per-token noise levels to mitigate error accumulation during autoregressive rollout. However, the model still suffers from noticeable quality degradation and lack of consistency over long rollouts, indicating challenges in maintaining stable representations as context length increases during inference.
To address this limitation, we introduce a biologically derived adapter module (see Bio Approach below), informed by experimentation with live neuronal cultures (Figure 2), that stabilizes predictions during inference-time sampling (Figure 3). The adapter is implemented as a shallow, lightweight module that modifies residual information in early DiT layers by incorporating localized spatial activations and a learned projection, adding approximately 156k parameters without altering the core model architecture (Figure 1).
The adapter is trained on Minecraft video sequences alongside moderate fine-tuning of the base model, with a lower learning rate applied to the pre-trained DiT weights to preserve learned representations. For comparison, we also evaluate base-model fine-tuning alone and low-rank adaptation (LoRA) (Figure 5).
Videos are generated autoregressively using saved checkpoints, with ten denoising steps per frame and stabilization noise applied to context frames. Generation quality is quantified by measuring dispersion in latent patch representations across frames, providing a proxy for information collapse. Across qualitative and quantitative evaluations, the TBC adapter consistently improves long-horizon rollout stability relative to base-model fine-tuning alone (Figures 4–7).
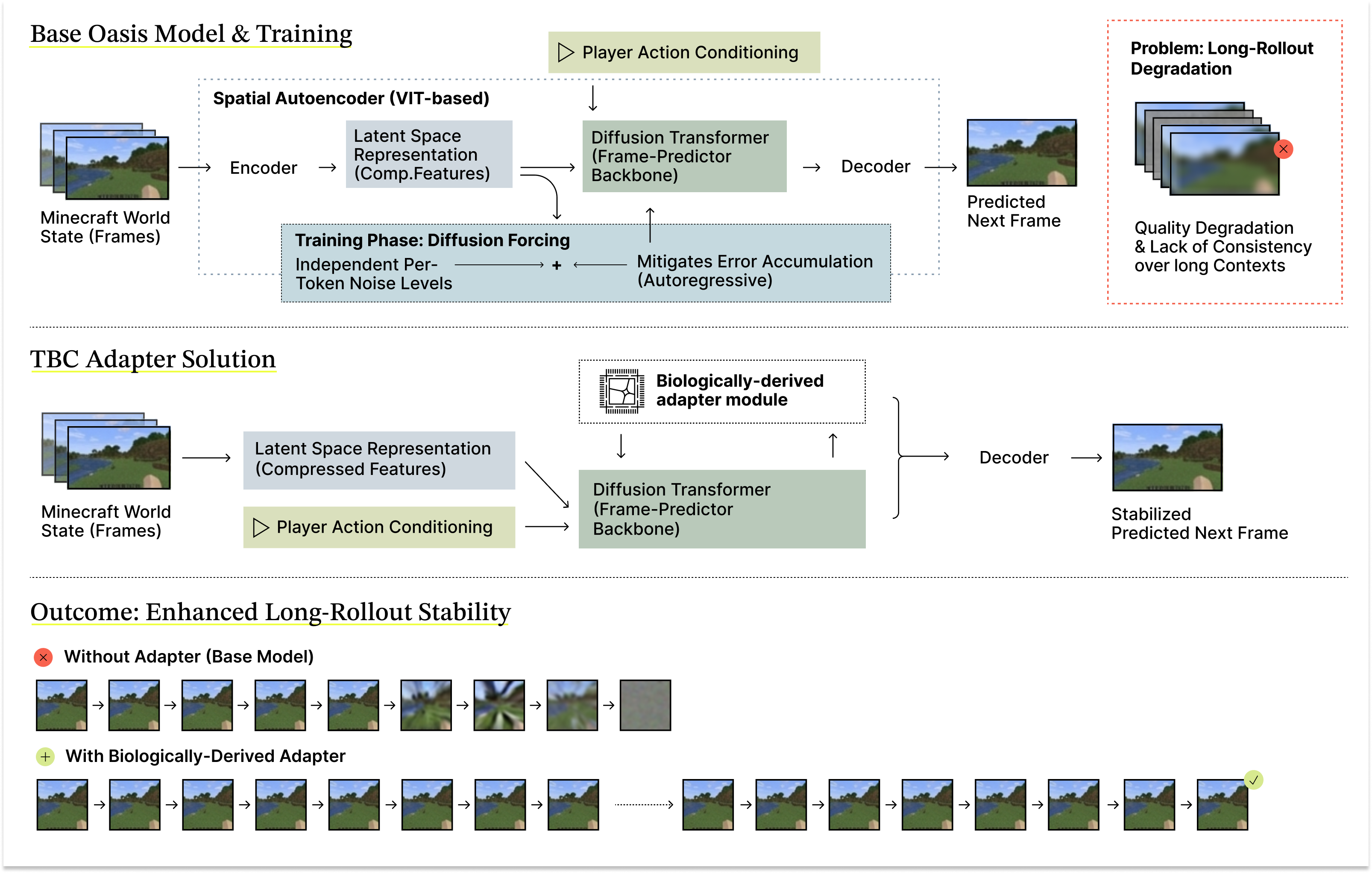
Figure 1. Schematic of the base Oasis video model and the TBC adapter solution. The base Oasis Diffusion Transformer model uses a ViT-based spatial autoencoder, action conditioning, and diffusion forcing to predict future frames, but exhibits quality degradation and loss of coherence during long autoregressive rollouts. Integrating a lightweight, biologically derived adapter into the frame-prediction backbone stabilizes intermediate representations during inference, resulting in more coherent long-horizon rollouts and preserved visual quality with minimal additional parameters.
The biological adapter used in this work is derived from living neural networks cultured on high-density multi-electrode arrays (Figure 2). These networks are used as a signal transformation substrate that captures structured neural responses to stimulation, or computational models derived from those responses.
Input data are encoded into structured electrical stimulation patterns delivered to the biological network. Neural responses are recorded as local spatiotemporal activity across the electrode array and decoded or modeled into numerical representations. These representations are then used to construct an adapter that can be integrated into a standard artificial neural network architecture.
The adapter is trained as a lightweight projection layer that maps biologically derived representations into a form compatible with intermediate representations within the pre-trained DiT model, optimized under standard training objectives (Figure 3).
At deployment time, the AI system operates entirely in silico, with the biologically derived adapter functioning as a fixed transformation applied to intermediate model representations. This design ensures reproducibility, compatibility with existing infrastructure, and clear isolation of biological effects.
Biological neural networks are well suited to this role because they naturally produce stable representations over extended temporal dynamics. When incorporated into an adapter, these properties translate into transformations that stabilize latent visual representations, preserving pixel- and patch-level structure across successive frames and reducing the accumulation of small errors during long-horizon rollout. This approach allows biological computation to be incorporated into modern AI systems in a controlled and scalable manner, contributing structural priors that improve long-term stability without disrupting existing training or deployment workflows.
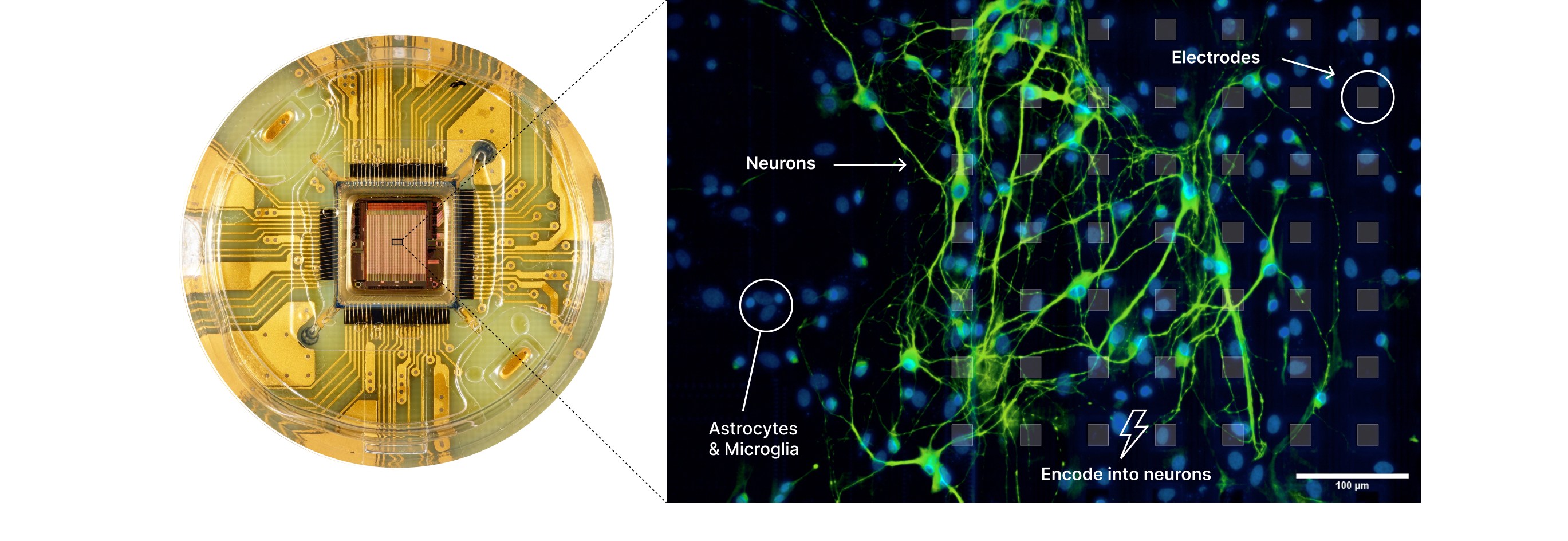
Figure 2. Real brain cells used for biological computing. Neurons are grown on a high-density multielectrode array containing 4,096 electrodes (left), forming active networks that process electrical signals over space and time (right). By encoding information into these living networks and reading out their activity, we derive neural-based representations that can be integrated into modern AI systems.
Figure 3. Schematic of biologically derived adapter construction. Image inputs are encoded into latent representations, mapped into living neural networks to elicit spatiotemporal neural responses, and decoded or modeled into a compact adapter that integrates into the AI model to stabilize latent representations during generation.
.gif)
Figure 4. Improved long-horizon video rollout with a biologically derived adapter. The Oasis DiT baseline degrades during extended rollout, while integrating a lightweight biological adapter preserves visual structure and maintains higher, more stable differential entropy over time.
We evaluated the effect of a biologically derived adapter on long-horizon video rollout using the Oasis DiT video model on a Minecraft-based environment. The baseline model (“Oasis Original”) exhibits progressive degradation during rollout, with frames becoming increasingly blurred and uninformative as temporal error accumulates. This behavior is representative of a common failure mode in long-context video generation.
In contrast, integrating the TBC adapter (“Oasis + TBC”) preserves visual structure and scene coherence across extended rollouts. Qualitatively, the model maintains sharper object boundaries, stable spatial relationships, and consistent scene semantics well beyond the point at which the baseline model degrades.
To quantify this effect, we measured differential entropy across generated frames as a proxy for visual information content. Results are reported as the normalized mean difference in differential entropy between the biologically augmented model and the baseline, averaged across 10 independent evaluation videos initialized with different starting scenes and actions. Across these rollouts, the TBC adapter yields an average ~19% improvement in image quality compared to the base Oasis model (Figure 5A), reflected by lower and more stable entropy over time. A parameter-matched fine-tuned control improves over baseline but underperforms the biological adapter by approximately ~15%, isolating the effect to the adapter rather than retraining (Figure 5B). The TBC adapter maintains an average ~5% improvement in normalized differential entropy relative to a LoRA-adapted model, indicating sustained gains in long-horizon stability where autoregressive degradation is most pronounced (Figure 5C).
These results demonstrate a consistent, reproducible improvement in long-horizon video stability achieved with negligible parameter overhead relative to the underlying DiT model. While fine-tuning techniques such as LoRA introduce low-rank adaptations to improve parameter efficiency, TBC’s approach instead encodes inductive biases about neural dynamics directly into the model, yielding comparable or superior performance with a similarly small parameter footprint. This provides a clear path toward robust fine-tuning and improved generalization using compact, interpretable adapter modules.
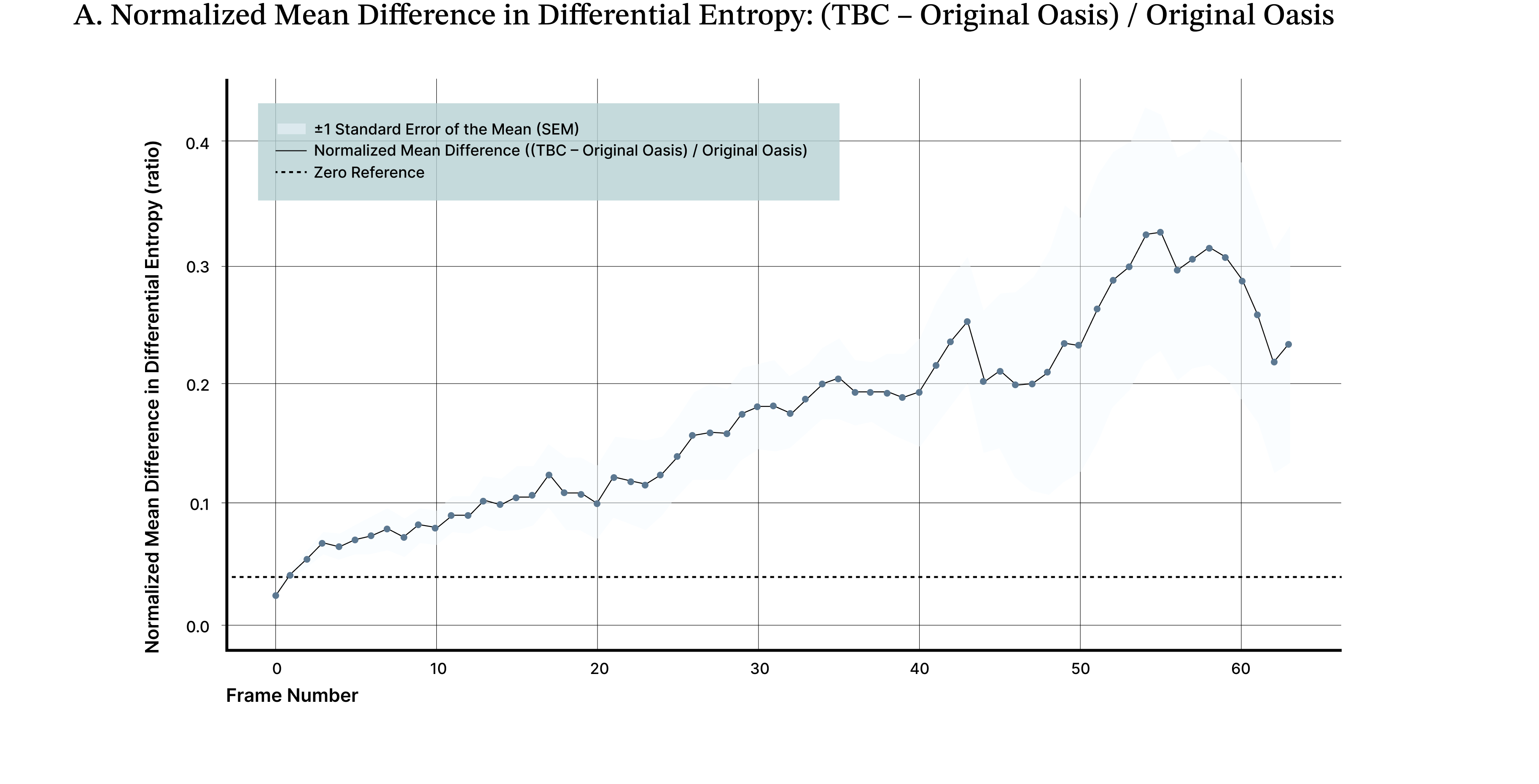
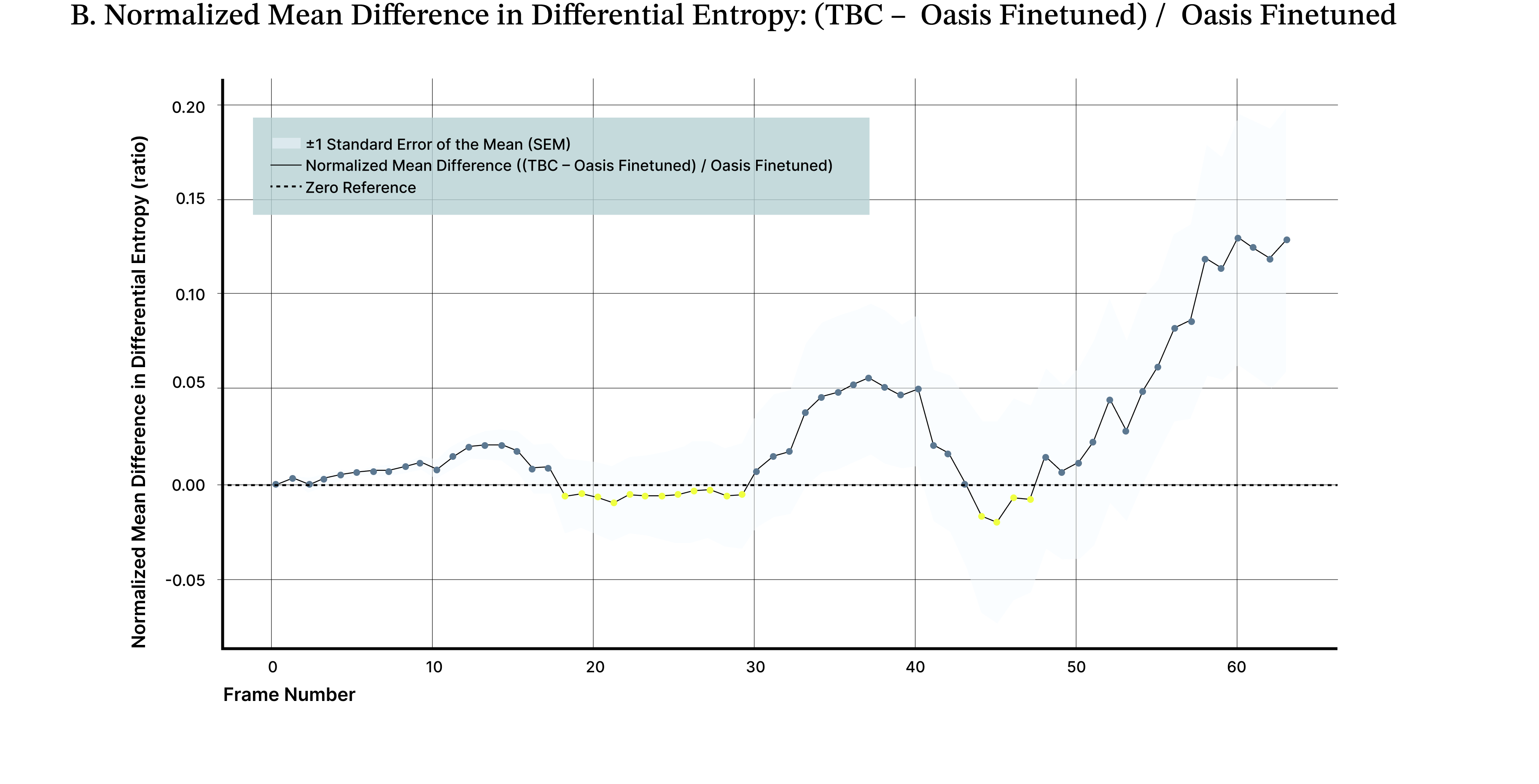
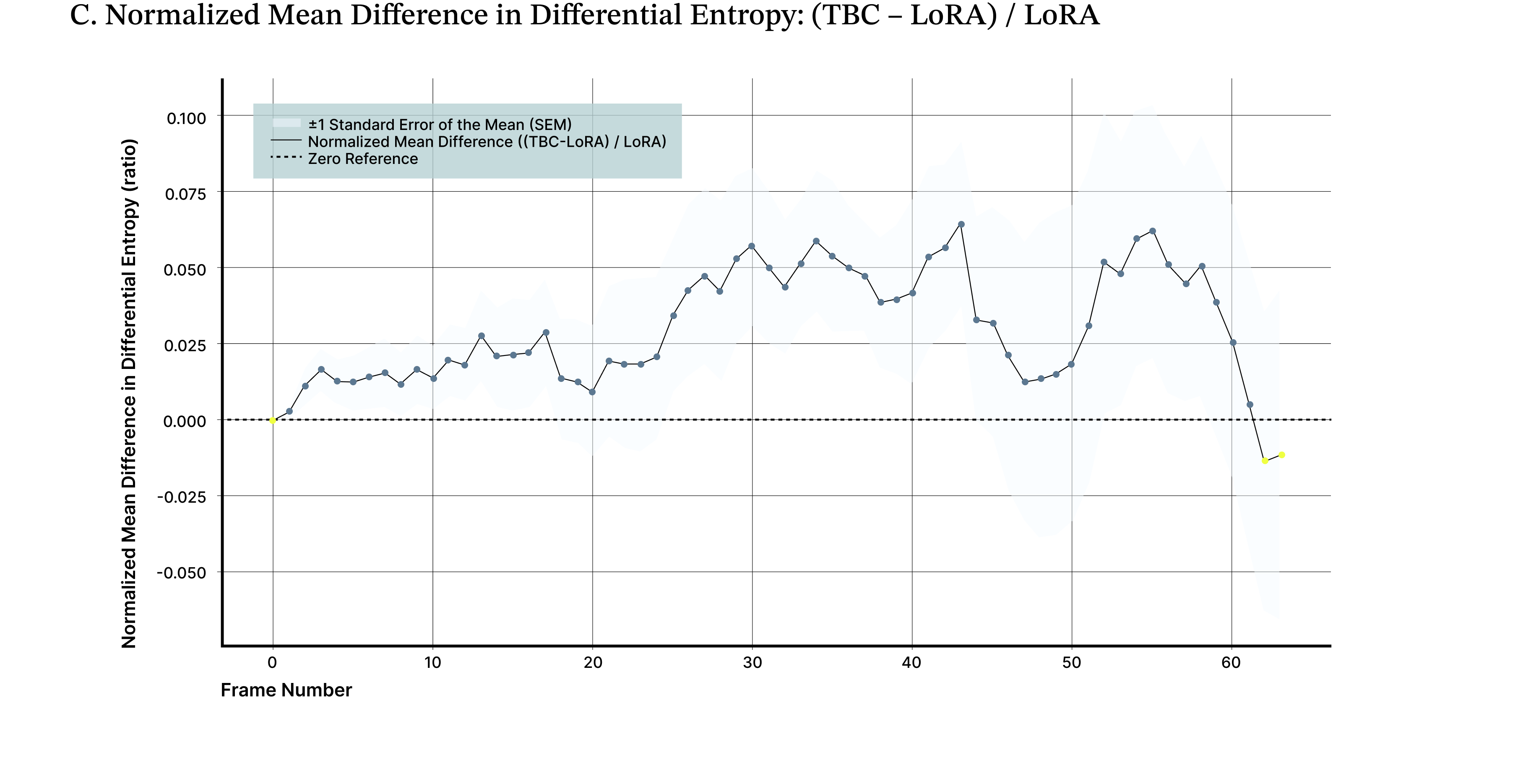
Figure 5. Biologically derived adapter prolongs stable video generation. A lightweight, biologically inspired adapter maintains higher and more stable differential entropy over extended video rollouts compared to the base model (A) and both full (B) and LoRA (C) fine-tuned variants. Differential entropy serves as a proxy for information richness in latent image patches and captures the onset of the “washout” effect commonly observed in long video sequences. Across 10 independent evaluation videos, the adapter consistently preserves visual complexity and motion diversity longer than alternative training approaches.
.gif)
.gif)
Figure 6. Improved long-horizon video rollout with a biologically derived adapter across two additional image seeds.
While our results show clear improvements in long-horizon rollout stability, several important questions remain. We are currently extending our evaluation across a broader range of denoising schedules and DDIM step counts to verify that the observed gains persist under different inference regimes, as rollout behavior can vary with sampling dynamics. Selecting the optimal number of DDIM steps involves a trade-off between visual fidelity and computational overhead: increasing the step count generally yields higher-quality video with fewer sampling artifacts, but at the cost of significantly higher compute. In production environments where real-time performance is critical, practitioners typically operate at lower DDIM settings, often between 10 and 20 steps, to ensure efficient inference. Our evaluation reflects this priority; while some competing methods in our benchmark may show higher visual quality at higher DDIM regimes (e.g., DDIM = 40, Figure 7), maintaining strong performance at 10 or 20 steps is a more relevant benchmark for our deployment-focused objectives.
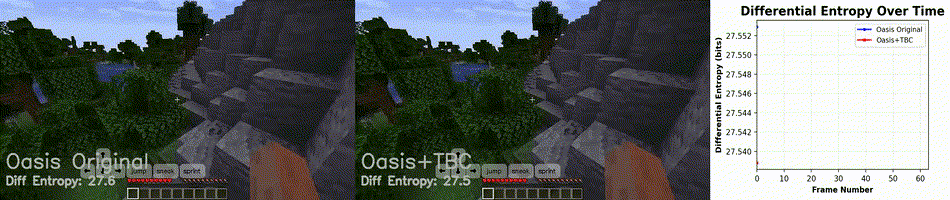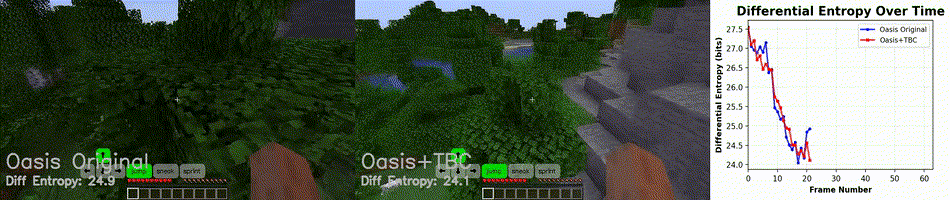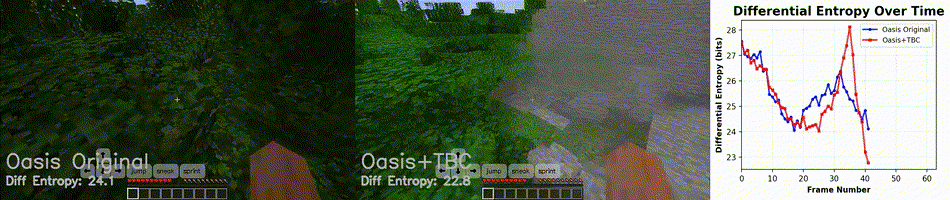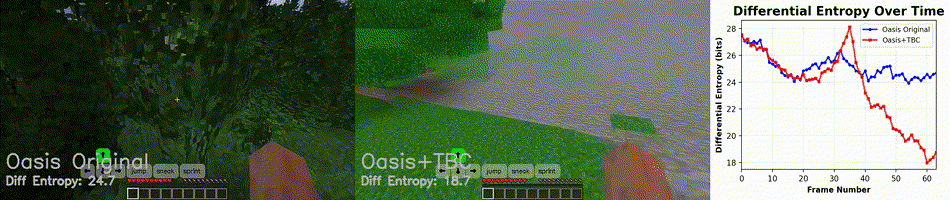
Figure 7. Video rollout at DDIM = 40. At high denoising step counts, the base Oasis model barely outperforms the adapter-augmented model in visual quality and information retention.
Our current experiments focus on a Minecraft-based environment, and we are actively testing whether these improvements generalize to additional environments and domains beyond gameplay. In parallel, we are examining whether integrating the adapter affects the model’s ability to generalize beyond fine-tuned distributions, ensuring that improvements in rollout stability do not come at the expense of broader model robustness.
To better understand the mechanisms underlying these improvements, we are probing how internal representations and denoising dynamics evolve during rollout. By examining attention patterns and latent drift timesteps, we aim to identify specific failure modes and stability bottlenecks. These insights inform the design of targeted architectural hooks and adapter interfaces that intervene at critical points in the generative process, rather than relying purely on end-to-end optimization.
We are also developing new adapter variants that more closely capture real spatiotemporal neural response patterns, including adapters derived directly from measured biological activity. Early results suggest that adapters which more faithfully reflect underlying biological dynamics yield greater downstream improvements in rollout stability.
Finally, while the adapter introduces only a minimal parameter overhead, we are working to quantify its impact on efficiency and energy demand more precisely. This includes training smaller Oasis models, performing systematic ablations, and measuring whether the adapter enables comparable rollout quality with reduced model size or compute, allowing us to directly estimate reductions in training and inference cost.
We demonstrate that a small, biologically derived software module can substantially improve the stability of long video generation in a state-of-the-art model without retraining or architectural changes. By enabling longer, more coherent rollouts, this approach lays the foundation for more reliable and efficient products in interactive games, simulations, robotics training, and persistent virtual environments. Importantly, neural-based adapters can reduce the computational cost required to achieve high-quality, temporally consistent outputs, while also providing a pathway for algorithm discovery and pointing toward a new paradigm for integrating biological principles into modern AI systems.