This blog series explores how biological neural networks can be integrated into modern AI systems. The posts progress from practical applications to increasingly general principles, moving from perception to representation, dynamics, and ultimately algorithm discovery. This post focuses on algorithm discovery, using biological neural systems as an experimental platform to uncover new learning dynamics for artificial intelligence.
Note: This is a living document, and we are building in the open. We expect frequent updates and actively welcome feedback from the community.
We show that insights from how biological neural systems stay flexible over time can be used to discover new algorithms for artificial intelligence. Rather than starting from theory alone, this work highlights a process for algorithm discovery grounded in neuroscience principles and validated in modern AI systems. It points toward a new pipeline for discovering algorithms using real neurons as an experimental guide, and toward a future where biological systems play a direct role in shaping how AI learns.
A biological, proactive learning approach allows AI systems to keep learning new tasks over time (continual learning) without losing what they already know (catastrophic forgetting), outperforming existing reactive methods on long sequences of learning problems.
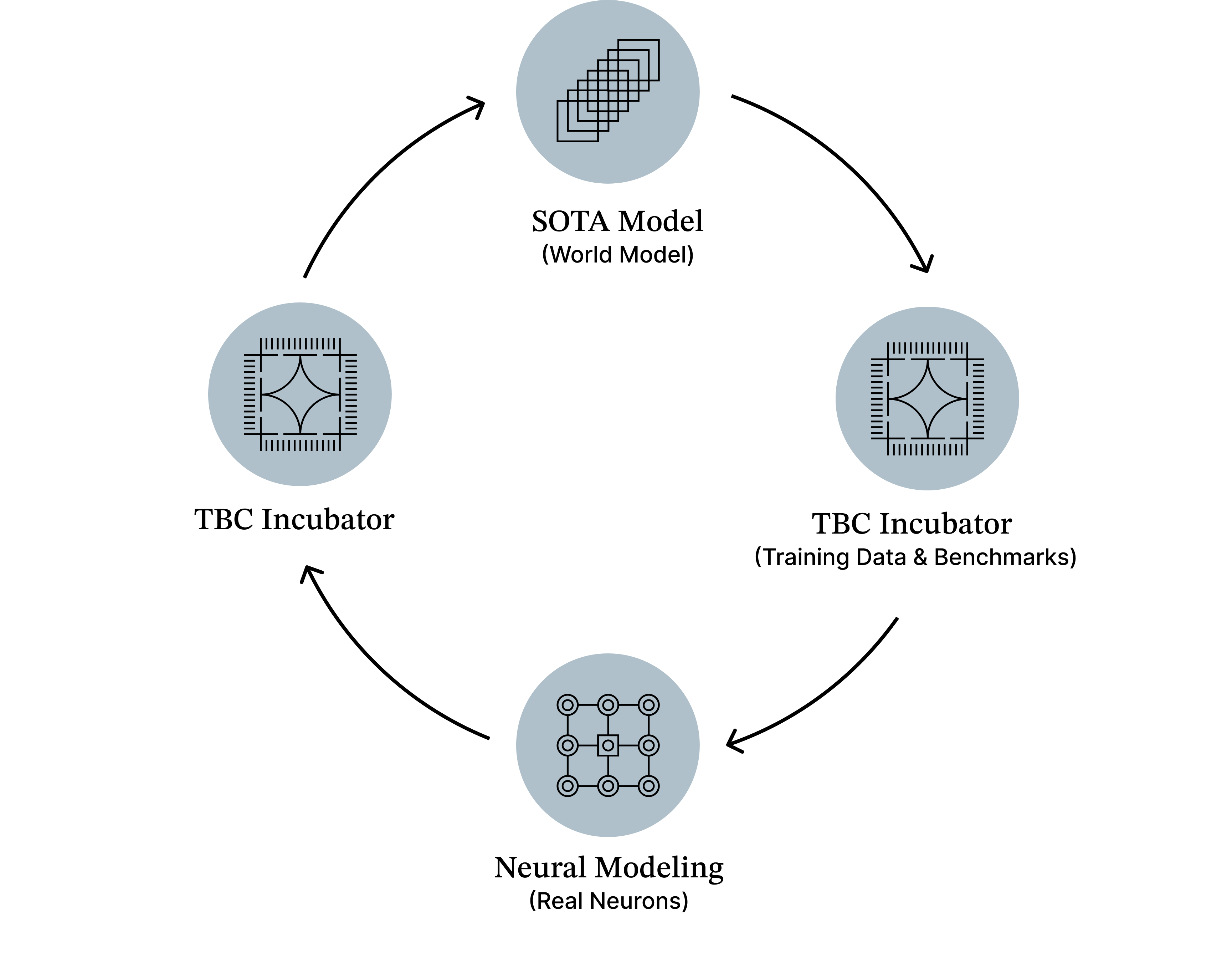
Algorithm discovery pipeline. Insights from real neurons (Neural Modeling) are translated into algorithms, evaluated in modern AI systems (TBC Incubator), and iteratively refined through a closed discovery loop.
We invite design partners, researchers, and builders who are thinking about what computing will look like five to ten years from now to engage with us. We have developed a biological neural platform for algorithm discovery, using real neural systems to augment today’s AI models and to help create entirely new, more biological ones. Together, we aim to unlock step-change gains in efficiency and enable applications that are not possible with current approaches. If you are interested in shaping the future of compute, we would love to explore what we can build together.
Modern artificial neural networks struggle with a fundamental limitation: over time, they lose the ability to keep learning. As models are trained on new tasks, their internal representations tend to collapse, neurons become redundant, and learning new information increasingly interferes with what was learned before. This loss of plasticity is a central challenge for building AI systems that can operate continuously in the real world.
Recent work by Richard Sutton and colleagues highlighted this problem and proposed a partial solution through Continual Backpropagation, a method that restores learning capacity by recycling low-utility neurons. While effective, this approach is inherently reactive. It intervenes only after representations have already degraded, treating the symptoms of plasticity loss rather than its underlying cause.
We approached this problem from a different angle. Instead of asking how to repair artificial networks after learning capacity is lost, we asked how biological neural systems avoid this failure mode in the first place. Real neural circuits maintain rich, flexible representations over long periods of time, even as they continuously incorporate new information. These systems offer a powerful source of insight into how learning can remain stable without relying on global oversight or periodic resets.
In this work, we use principles drawn from neuroscience to guide the discovery of new algorithms for artificial learning systems. Rather than focusing on a specific task or architecture, we study how local interactions between neurons can shape learning dynamics in a way that preserves representational richness and sustained learning capacity. Continual learning serves as a concrete testbed for this broader idea.
Together, these results point toward a new approach to algorithm discovery, one that looks beyond purely theoretical derivations and toward biological systems as a guide for uncovering learning rules that scale over time. This direction lays the groundwork for a future pipeline in which real neural systems can play an active role in shaping how artificial intelligence learns.
Our solution draws from an unexpected source: the behavior of real neurons. Neuroscientists have long observed that biological neural circuits employ local learning behaviors that naturally maintain feature diversity over time. These cellular mechanisms operate without any global oversight. Each neuron adjusts its connections based solely on local activity patterns. The result is a self-organizing system that resists the kind of representational collapse commonly observed in artificial networks during prolonged learning.
Rather than treating these observations as a blueprint to replicate, we view them as a starting point for algorithm discovery. Biological systems provide concrete evidence that continual learning without collapse is possible, and they suggest classes of learning behaviors that are difficult to derive from theory alone.
Guided by these principles, we identified a cellular local plasticity rule for artificial networks. Like its biological counterpart, this learning rule operates locally at each neuron and requires no global utility calculations or centralized decisions about which neurons to recycle. Instead, it shapes learning in a way that preserves representational structure over time, reduces interference between tasks, and sustains learning capacity as training progresses.
Guided by these principles, we developed a local plasticity rule that can be integrated into standard artificial neural networks without modifying their overall architecture. The learning rule operates at the level of individual neurons, shaping how representations evolve during training through local interactions rather than global coordination.
Unlike reactive methods that intervene only after learning capacity has degraded and require a global assessment to compare coding elements and identify under-performant ones, our approach acts continuously during training at the level of local computations to preserve representational structure as new tasks are introduced. The learning rule is applied directly within existing training loops and does not require access to biological systems during training or inference.
We evaluate this approach in continual learning settings, where networks must learn tasks in sequence with each new task introducing novel data. This regime provides a clear test of whether learning capacity is sustained over time and allows direct comparison with existing methods designed to mitigate plasticity loss.
We evaluated our approach against Continual Backpropagation across 200 sequential tasks using the Permuted MNIST benchmark, the same class of problem studied by Sutton and colleagues. The results exceeded our expectations.
Plasticity. Models using our local plasticity rule achieved approximately 97% accuracy on newly introduced tasks, comparing favorably to Continual Backpropagation at 96%. As shown previously, accuracy using standard backpropagation degrades substantially over the same training horizon. To understand why this learning capacity is preserved, we examined the structure of internal representations over time.
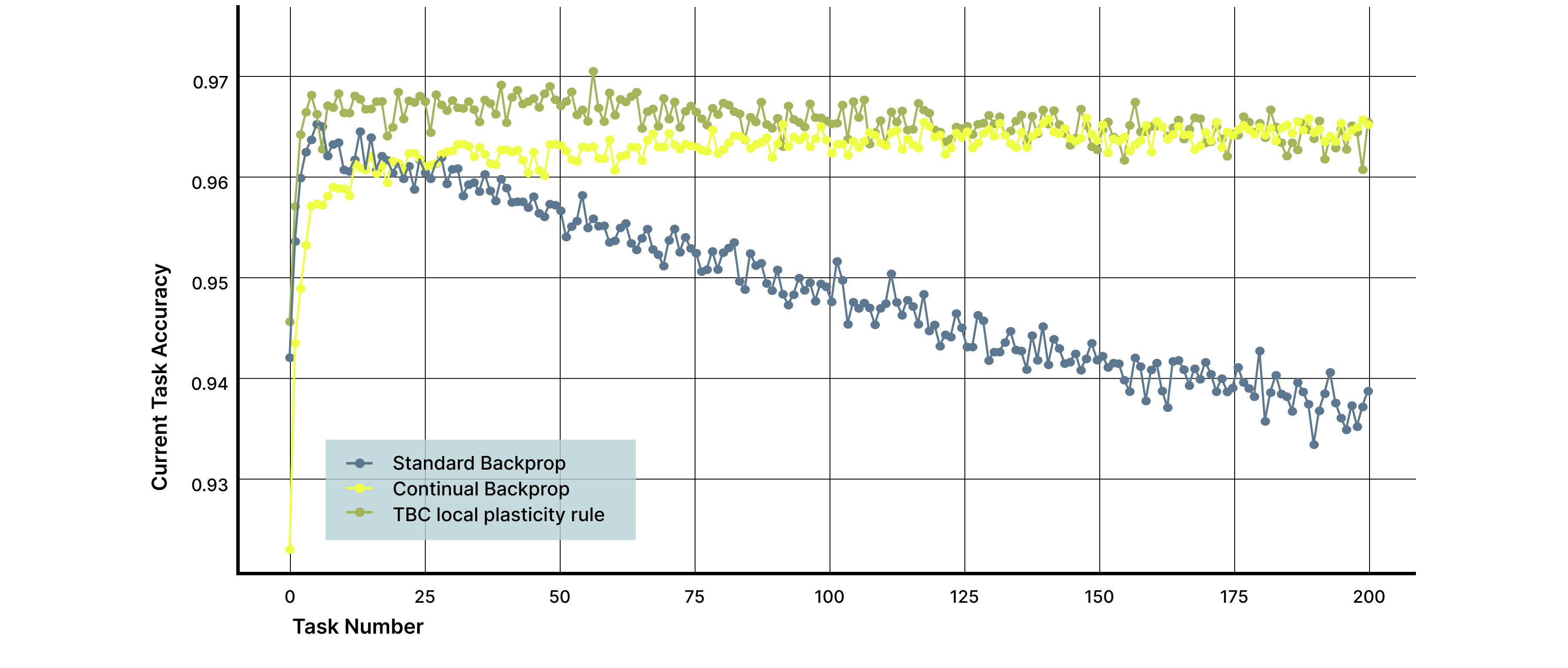
Figure 1. Plasticity measured as accuracy on newly introduced tasks. Models trained with the local plasticity learning rule maintain high and stable accuracy as 200 novel datasets are learned in sequence using a permuted MNIST dataset. Performance compares favorably to Continual Backpropagation and substantially outperforms standard backpropagation, which shows progressive degradation as training proceeds. These results indicate sustained learning capacity over long training horizons.
Representation quality. Networks trained with our approach maintained consistently high effective rank throughout training, roughly double that of reactive methods. Internal representations remained rich and non-redundant over time, rather than collapsing into low-dimensional subspaces.
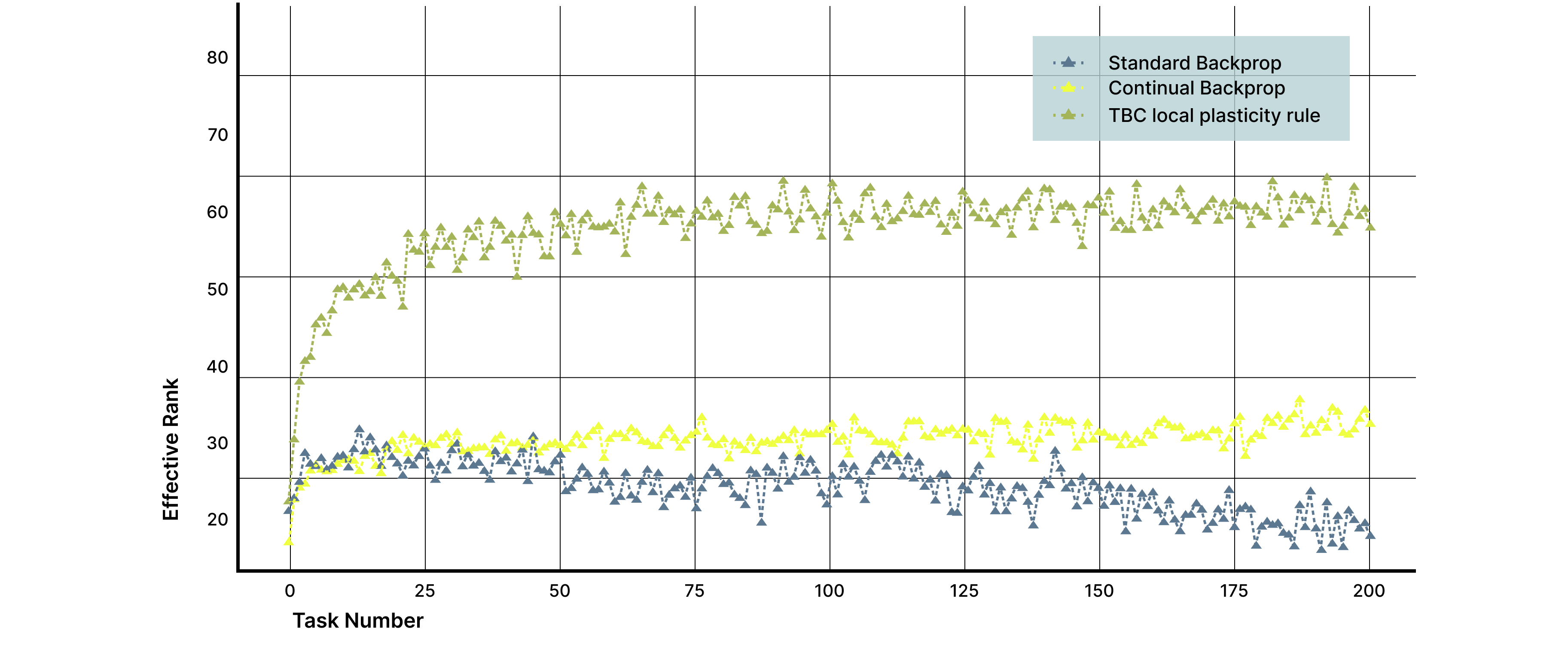
Figure 2. Representation quality measured by effective rank of hidden activations. Networks trained with the local plasticity learning rule maintain consistently higher effective rank throughout training, indicating richer and less redundant internal representations. In contrast, reactive methods show progressive rank collapse as tasks accumulate. Preserved representational richness correlates with both the ability to learn and improved performance of prior tasks.
Catastrophic forgetting. Perhaps most notably, our proactive approach significantly outperformed Continual Backpropagation in retaining the ability to perform previously learned tasks. While reactive methods exhibit rapid forgetting of earlier skills, our method maintained substantially higher performance on prior tasks. In some temporal regimes, retention was nearly doubled. These results suggest that preserving high-rank representations not only supports continued learning, but also reduces interference between old and new knowledge.
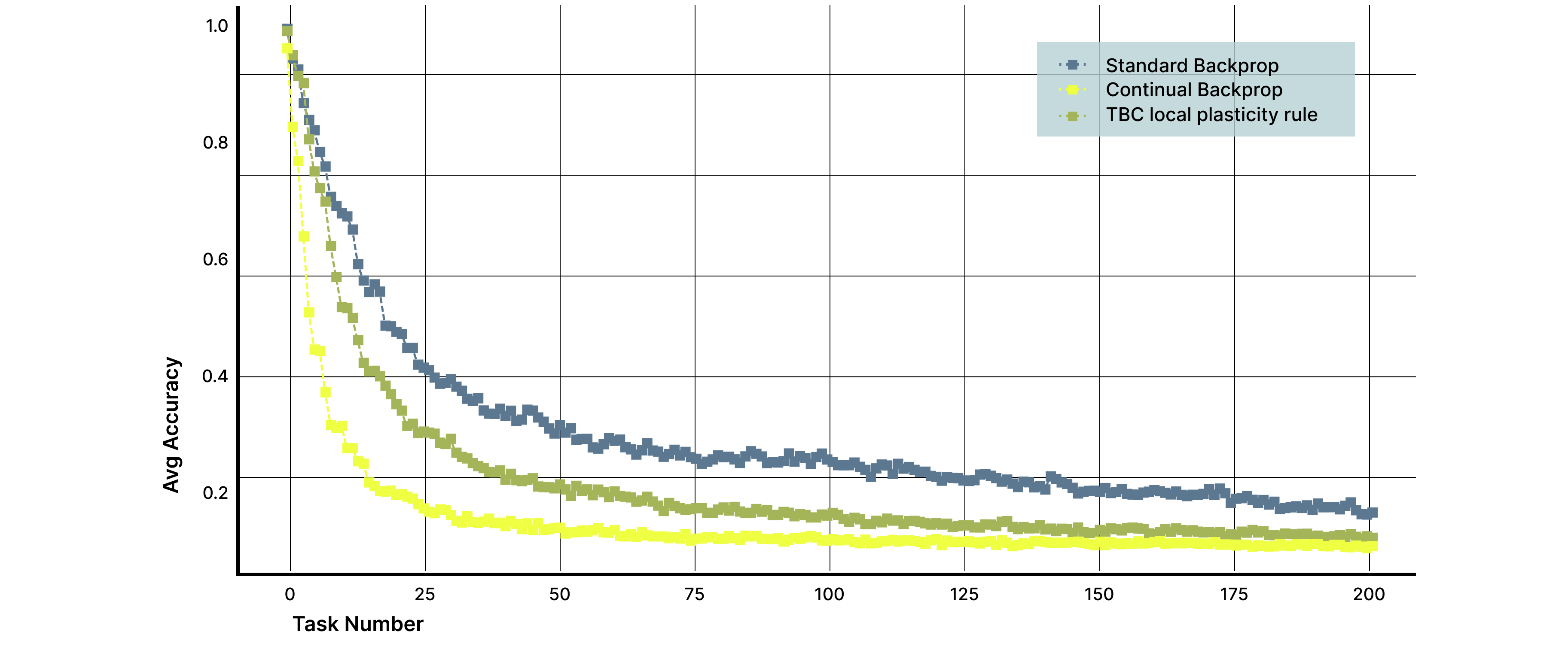
Figure 3. Memory retention measured as average accuracy across all previously learned tasks. Models using the local plasticity rule retain substantially higher performance on earlier tasks compared to reactive methods such as Continual Backpropagation. While baseline and recycling-based approaches exhibit rapid forgetting, the proposed method preserves prior knowledge over extended task sequences, demonstrating reduced interference between old and new learning.
This work represents an early step toward using biological insight to guide algorithm discovery. Our evaluation focuses on a controlled continual learning benchmark, which provides a clear test of sustained learning capacity but does not capture the full complexity of real-world settings. Extending these results to broader tasks, data modalities, and model architectures will be important for assessing how broadly these effects generalize.
While we observe clear gains in plasticity, representation quality, and retention, the theoretical foundations of this approach remain an active area of investigation. We are continuing to study the learning dynamics underlying these results and extending our experiments to more complex domains. Although we are not yet ready to publish the full technical details of the local plasticity rule, we wanted to share these findings with the research community as an initial step.
More broadly, this work points toward a new direction for discovering learning mechanisms. Looking ahead, developing systematic pipelines to explore and refine biological learning rules will be critical for turning these ideas into a repeatable engine for algorithm discovery.
These results highlight a key limitation of reactive continual learning methods, which intervene only after representations have already collapsed, making recovery difficult once learning capacity is lost. By contrast, a proactive approach that preserves rich, high-dimensional representations throughout training allows new tasks to be learned without overwriting existing knowledge. More broadly, this work demonstrates how biological insight can guide algorithm discovery, pointing toward a future in which biology enables the systematic development of more adaptive and resilient AI systems.